Photo forensics from lighting environments
In this era of generative AI, how do we determine whether an image is human-created or machine-made? For the Content Authenticity Initiative (CAI), Professor Hany Farid shares the techniques used for identifying real and synthetic images — including analyzing shadows, reflections, vanishing points, environmental lighting, and GAN-generated faces. A world-renowned expert in the field of misinformation, disinformation, and digital forensics as well as an advisor to the CAI, Professor Farid explores the limits of these techniques and their part in a larger ecosystem needed to regain trust in the visual record.
This is the fourth article in a six-part series.
More from this series:
Part 1: From the darkroom to generative AI
Part 2: How realistic are AI-generated faces?
Part 3: Photo forensics for AI-generated faces
by Hany Farid
Classic computer-generated imagery (CGI) is produced by modeling 3D scene geometry, the surrounding illumination, and a virtual camera. As a result, rendered images accurately capture the geometry and physics of natural scenes. By contrast, AI-generated imagery is produced by learning the statistical distribution of natural scenes. Without an explicit 3D model of the world, we might expect that these images will not always accurately capture the 3D properties of natural scenes.
The lighting of a scene can be complex, because any number of lights can be placed in any number of positions, leading to different lighting environments. Under some fairly modest assumptions, however, it has been shown that a wide range of lighting can be modeled as a weighted sum of nine 3D lighting environments that each capture a variety of lighting patterns from different directions.
My team and I first wondered if lighting environments on AI-generated faces match those on photographic images. Next, we wondered if the lighting on multiple faces or objects in an image are the same, as would be expected in an authentic photo.
Analyzing lighting environments first requires fitting and aligning a 3D model to individual objects. Fortunately, for faces, fitting a 3D model to a single image is a problem that has largely been solved. (See article 1 in the Further Reading section.)
Below you’ll see a 3D model fitted to an AI-generated face. From this aligned 3D model, we can estimate the surrounding lighting environment, which reduces to nine numeric values corresponding to the weight on each of nine 3D lighting environments.
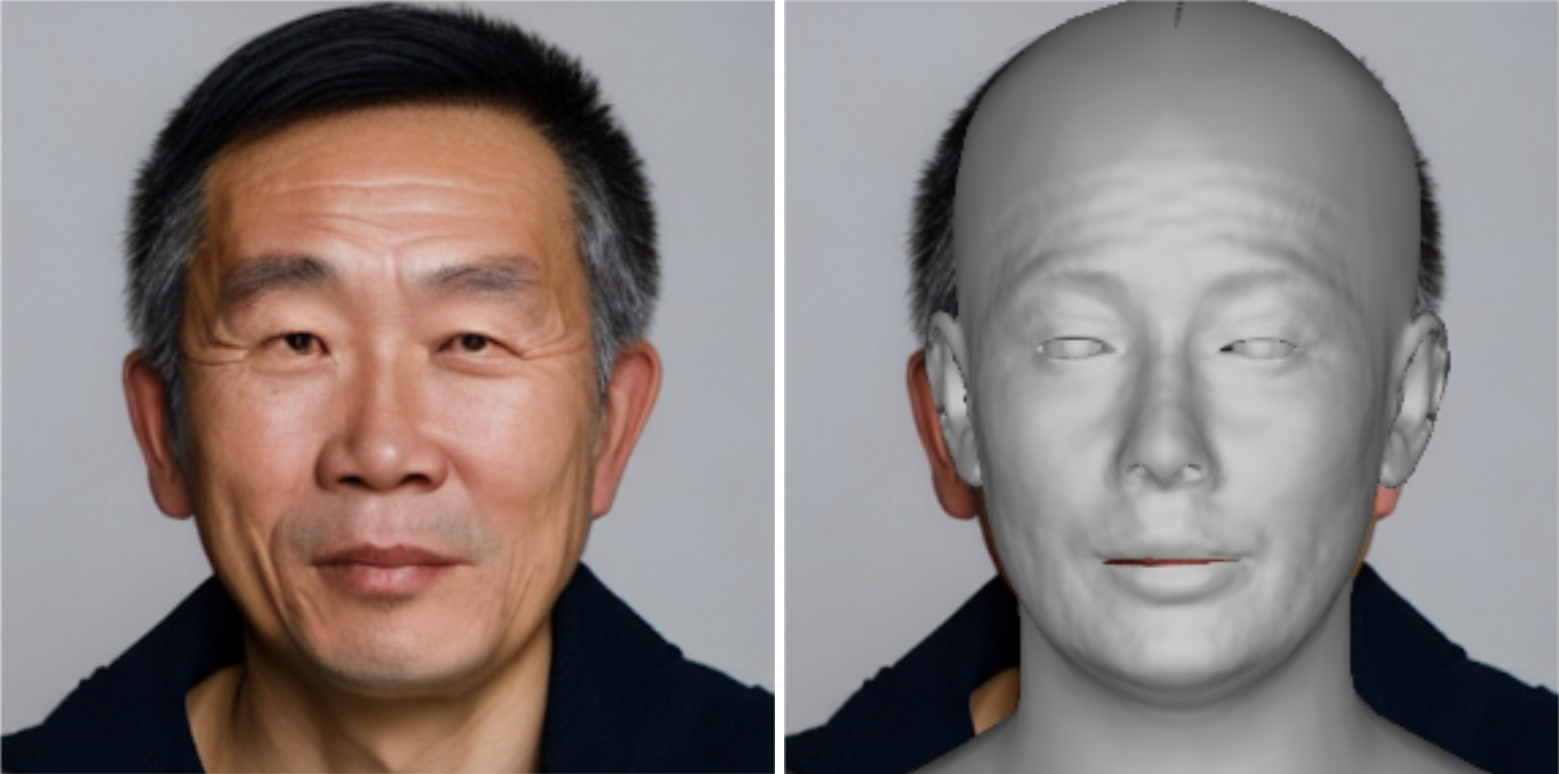
An AI-generated face and a fitted 3D model. (Credit: Hany Farid)
As you can see in the plot on the left below, there are some significant deviations between the nine lighting values for real faces (horizontal axis) and diffusion-generated faces (vertical axis). Interestingly, as you can see in the plot on the right, the lighting on GAN-generated faces (see previous post) are nearly indistinguishable from the lighting on real faces.
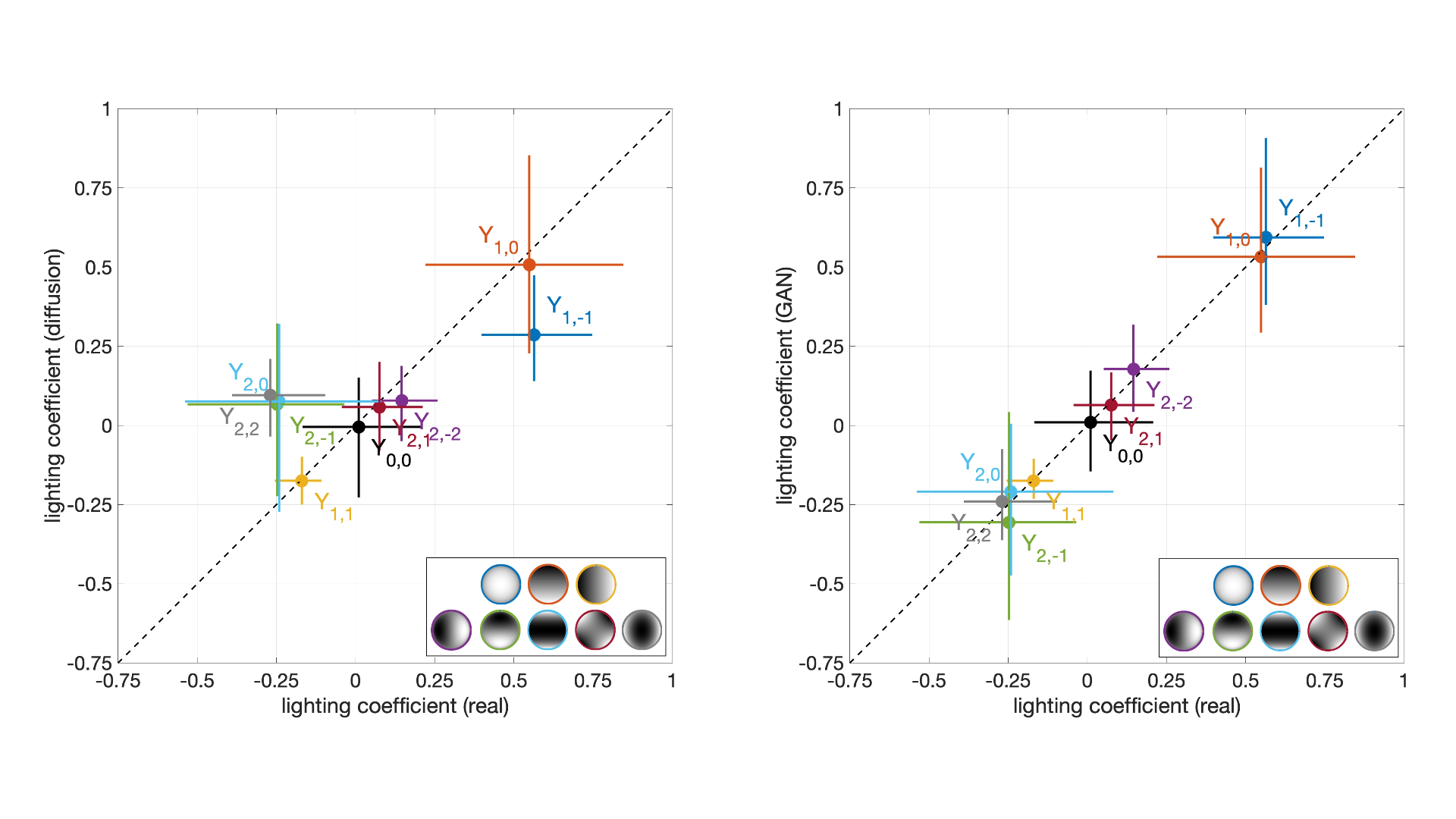
The relationship between lighting environments on real (horizontal axis) and AI-generated (vertical axis) faces. The plot on the left corresponds to diffusion-based faces, the plot on the right corresponds to GAN-generated faces. (Credit: Hany Farid)
While a comparison of lighting environments may expose a diffusion-based face (or object), it appears that this approach will not provide much insight for GAN-based faces. This is the reverse of our previously described technique, which was applicable to GAN-based faces but not diffusion-based faces, further highlighting the need for a wide variety of approaches.
The above analysis can be expanded to compare the lighting between two people or two objects situated side by side in an image where, in a naturally photographed scene, we expect the lighting to be the same. For this analysis, we find that diffusion-based faces and objects exhibit relatively large (but not always perceptually obvious) differences in lighting. (See article 3 in the “Further reading” section below for more details.)
The strength of this lighting analysis is that we have discovered a fairly fundamental limitation of today's AI-generated content: In the absence of explicit 3D models of the physical world, diffusion-based models struggle to create images that are internally (across multiple people/objects) and externally (as compared to photographic images) consistent. The weakness of this technique is that, unlike other approaches, it does not necessarily lend itself to a fully automatic and high-throughput analysis. The fitting of 3D models can be somewhat time intensive and require manual intervention.
Another strength of this technique is that even when made aware of the issue of lighting inconsistencies, it is not easy for an adversary to adjust the image. That is because the pattern of illumination is the result of an interaction of the 3D lighting and the 3D scene geometry, whereas most photo editing occurs in 2D. Also, as you will see in the next post, there are additional aspects to lighting that we can exploit to distinguish the real from the fake.
Further reading:
[1] Y. Feng, H. Feng, M.J. Black, and T. Bolkart. Learning an animatable detailed 3D face model from in-the-wild images. ACM Transactions on Graphics, Proc. SIGGRAPH, 40(4):88:1– 840 88:13, 2021.
[2] M. Boháček and H. Farid. A Geometric and Photometric Exploration of GAN and Diffusion Synthesized Faces. Workshop on Media Forensics at CVPR, 2023.
[3] H. Farid. Lighting (In)consistency of Paint by Text. arXiv:2207.13744, 2022.
More from this series:
Part 1: From the darkroom to generative AI
Part 2: How realistic are AI-generated faces?
Part 3: Photo forensics for AI-generated faces
Author bio: Professor Hany Farid is a world-renowned expert in the field of misinformation, disinformation, and digital forensics. He joined the Content Authenticity Initiative (CAI) as an advisor in June 2023. The CAI is a community of media and tech companies, non-profits, academics, and others working to promote adoption of the open industry standard for content authenticity and provenance.
Professor Farid teaches at the University of California, Berkeley, with a joint appointment in electrical engineering and computer sciences at the School of Information. He’s also a member of the Berkeley Artificial Intelligence Lab, Berkeley Institute for Data Science, Center for Innovation in Vision and Optics, Development Engineering Program, and Vision Science Program, and he’s a senior faculty advisor for the Center for Long-Term Cybersecurity. His research focuses on digital forensics, forensic science, misinformation, image analysis, and human perception.
He received his undergraduate degree in computer science and applied mathematics from the University of Rochester in 1989, his M.S. in computer science from SUNY Albany, and his Ph.D. in computer science from the University of Pennsylvania in 1997. Following a two-year post-doctoral fellowship in brain and cognitive sciences at MIT, he joined the faculty at Dartmouth College in 1999 where he remained until 2019.
Professor Farid is the recipient of an Alfred P. Sloan Fellowship and a John Simon Guggenheim Fellowship, and he’s a fellow of the National Academy of Inventors.