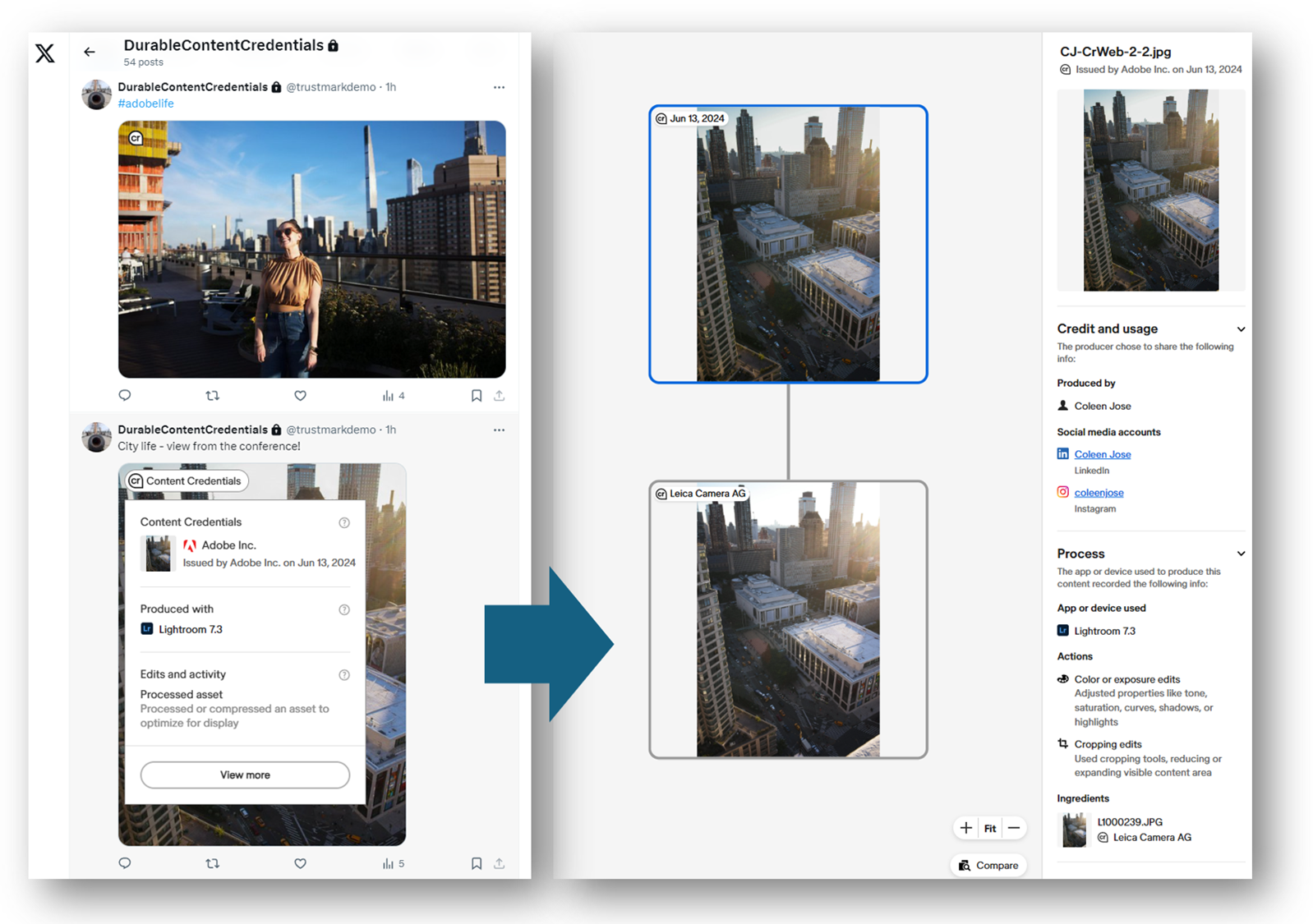
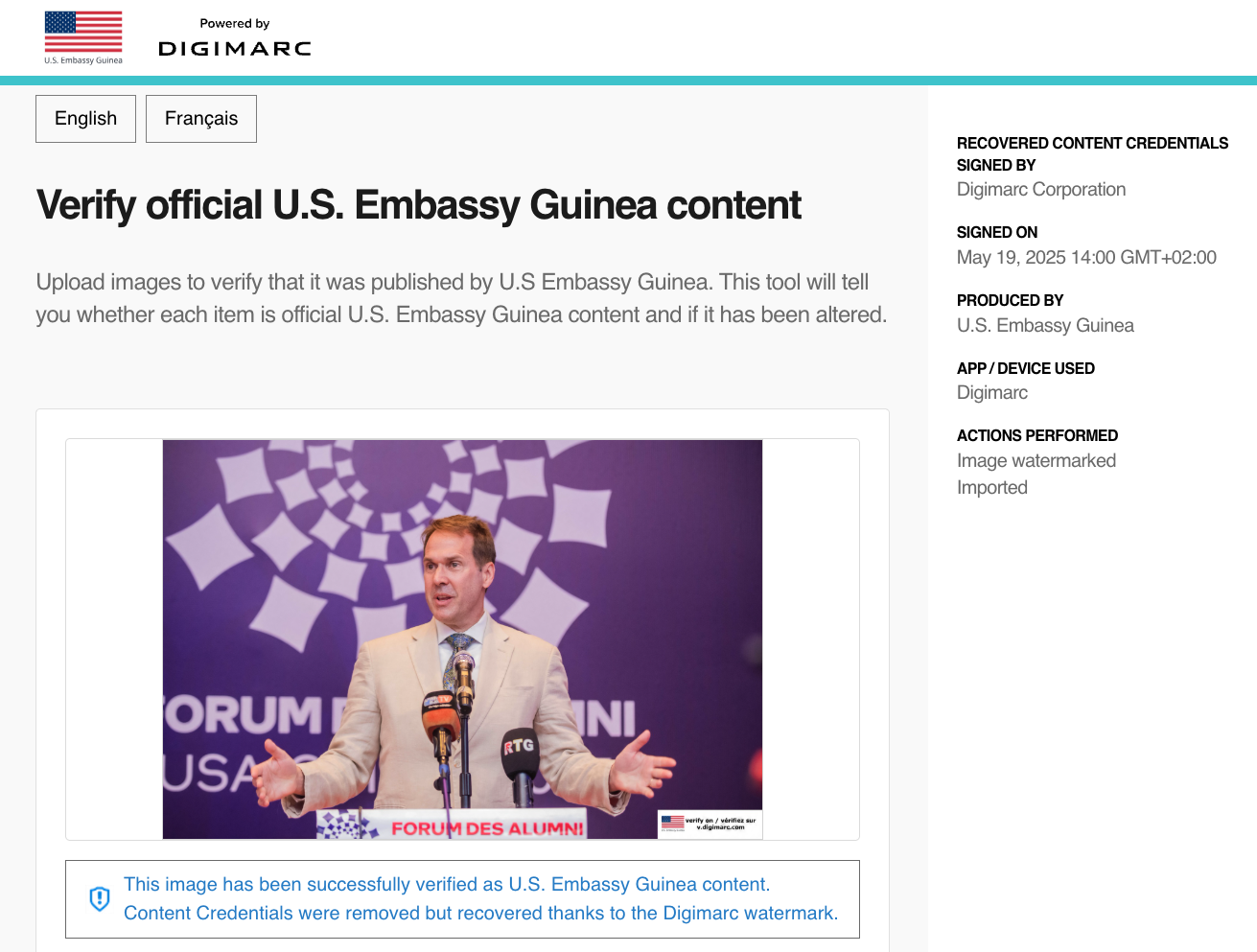
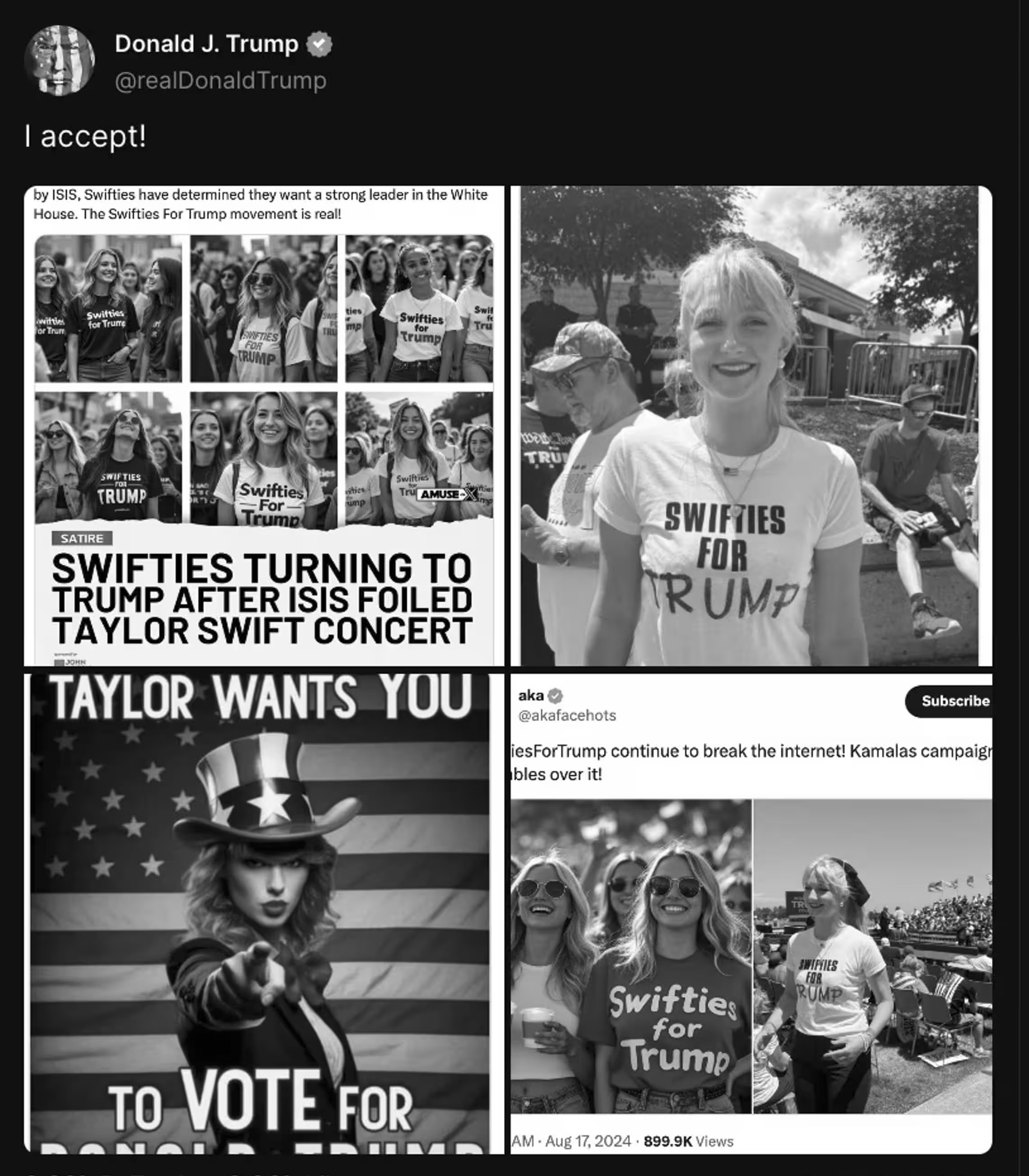
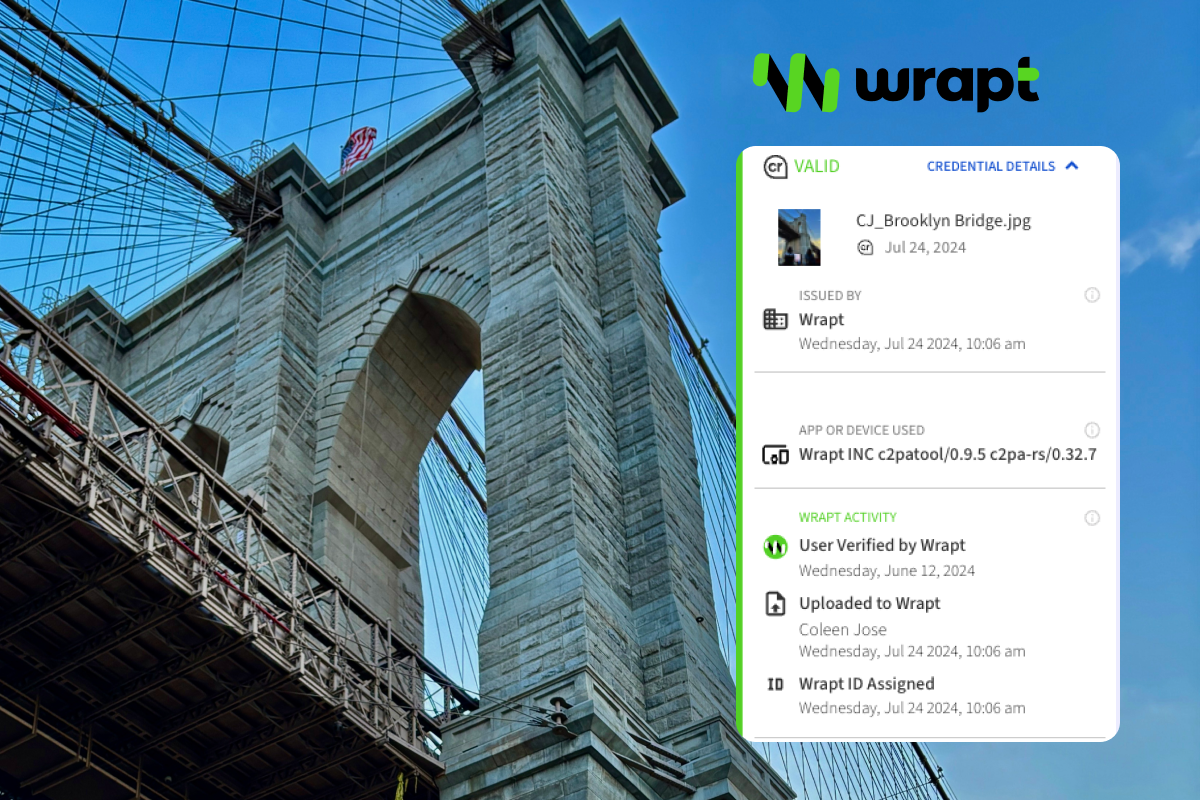
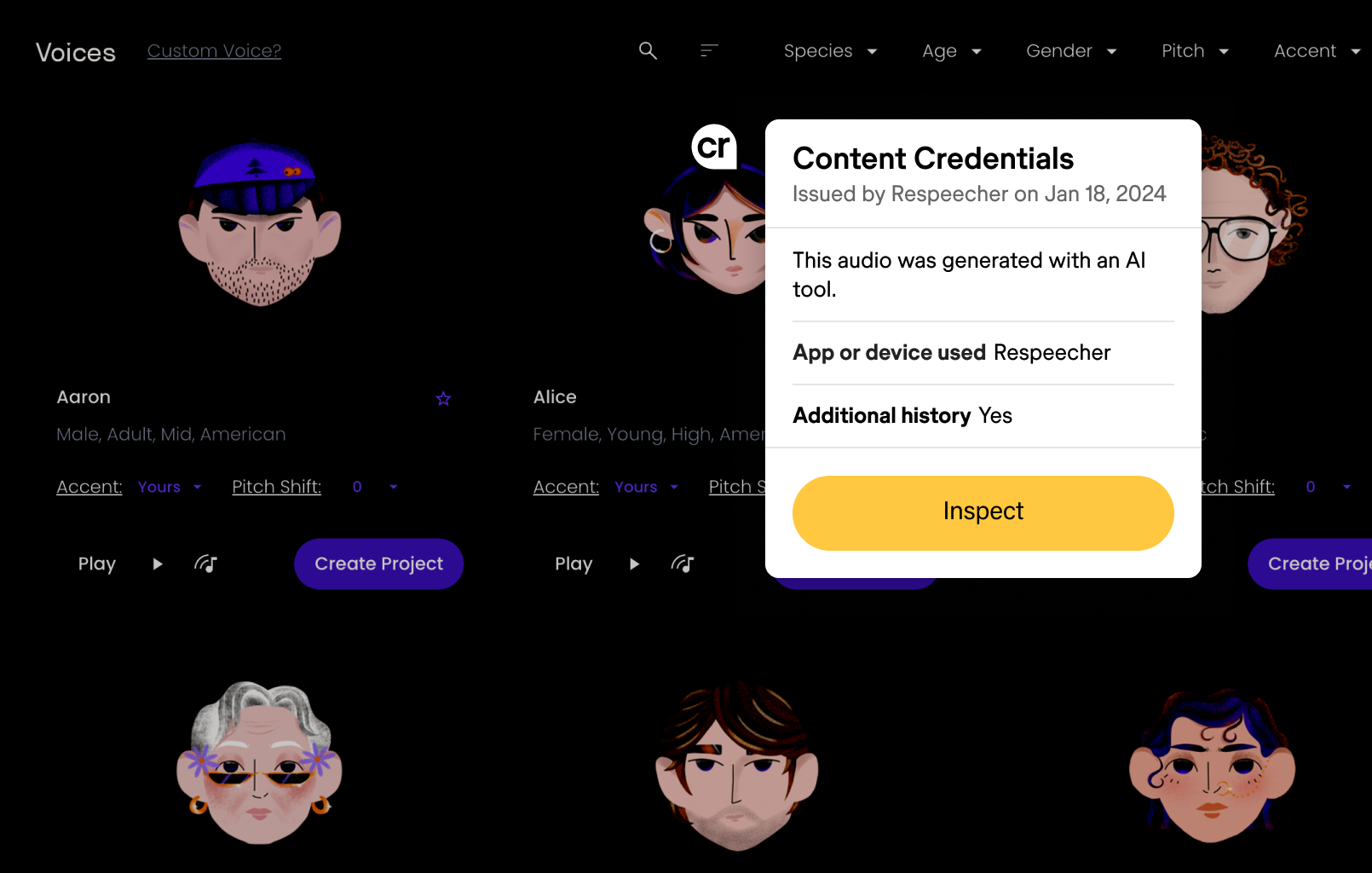
February 2024 | This Month in Generative AI: Election Season
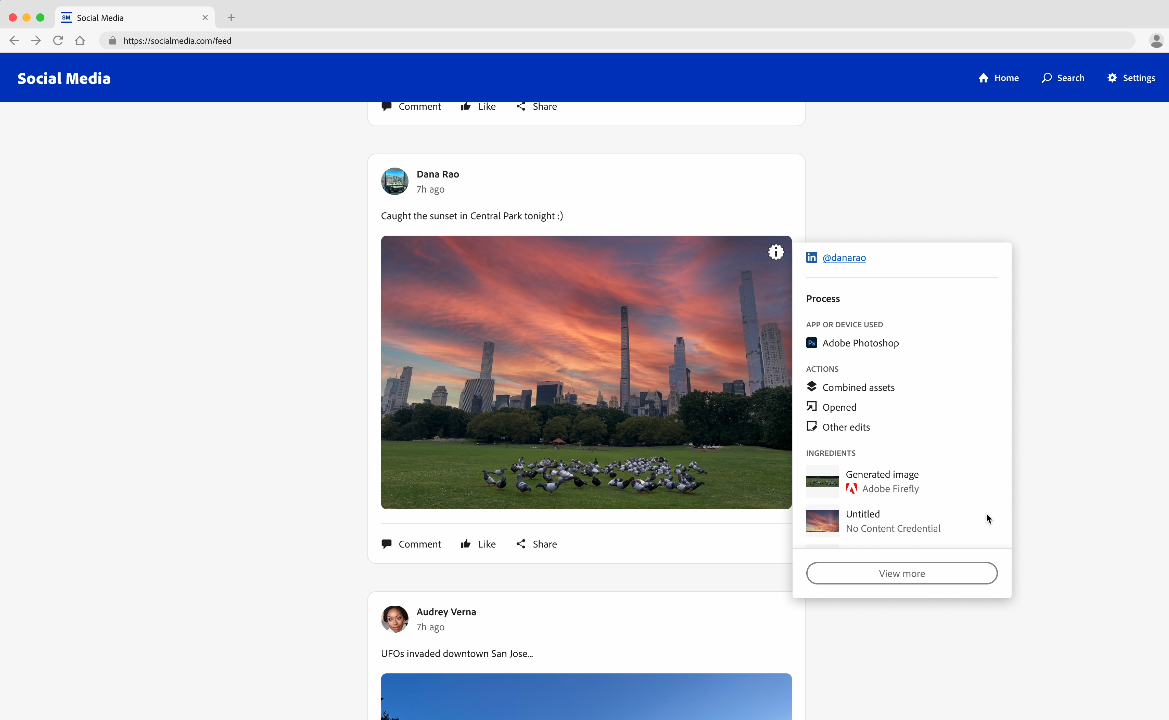
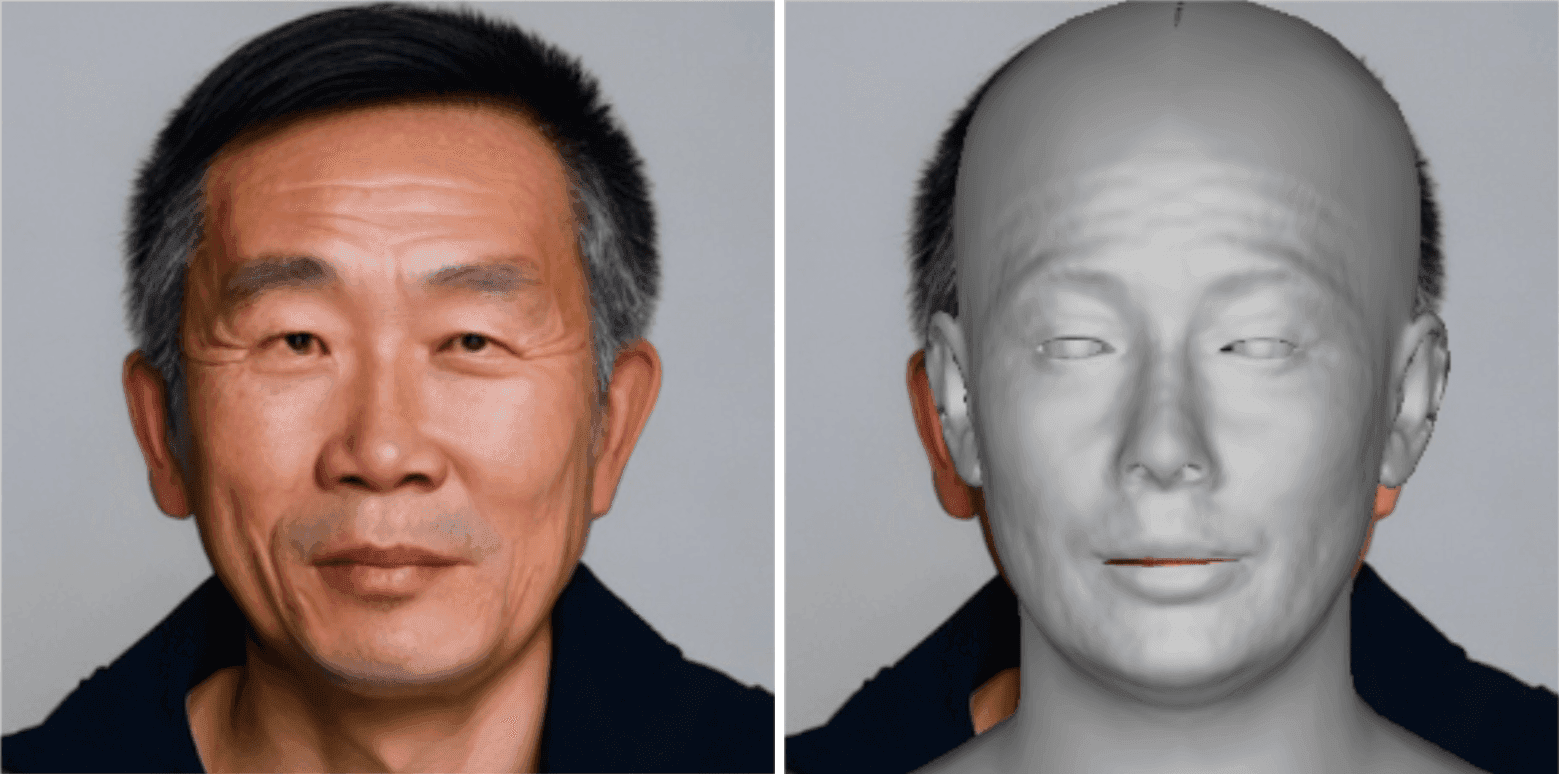
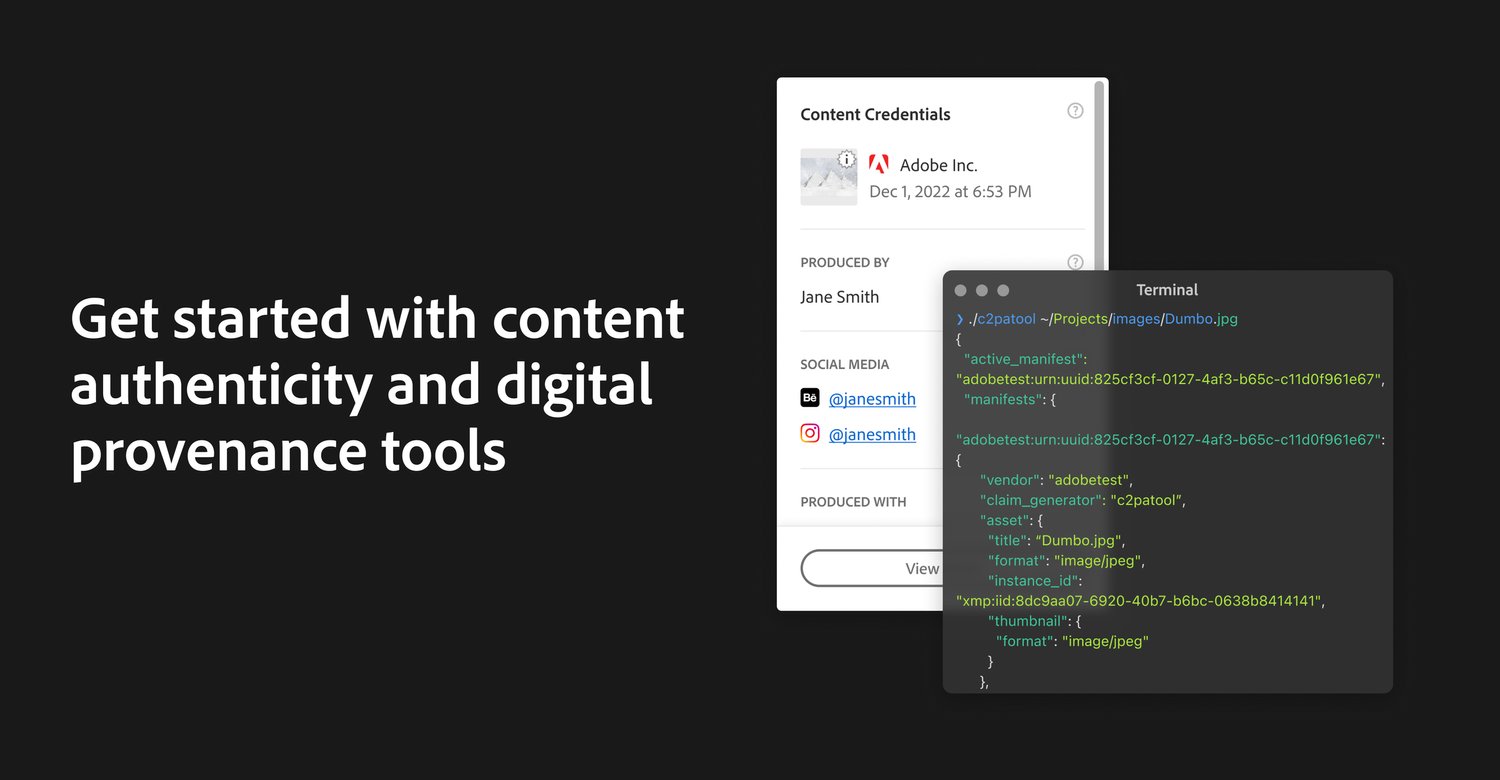
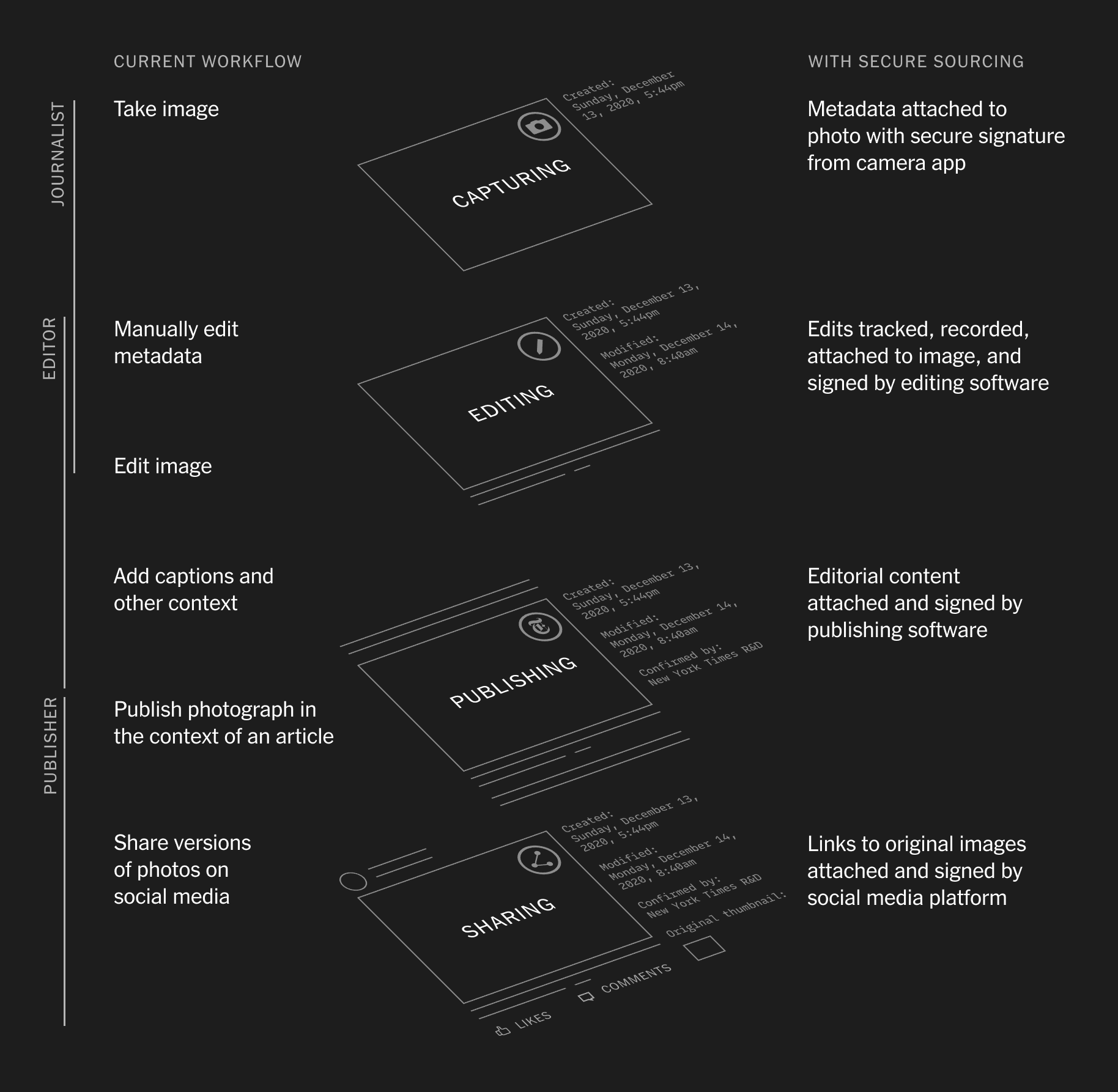
From AI resurrected dictators to AI powered interactive chatbots, political campaigns around the world are deploying the technology to expand their audience and win over voters. This month, Hany Farid, UC Berkeley Professor, CAI Advisor, looks at examples of increasingly easier to combine fake audio with video, its clear effect on the electorate, and existing solutions to authenticating digital media.